pdp 수업시간에 발표해야 돼서 더 꼼꼼히, 자세하게 읽어본 논문
저자는 amd researcher, SC24 컨퍼런스에서 발표된 적이 있음
30분 안에 발표 가능..?
Introduction
[trends]
복잡한 문제를 풀기 위해 ML 모델의 사이즈는 계속 커지고 있다
large ML 모델 등장으로 memory capacity와 compute requirement를 충족시키기 위해 distributed system 발전
distributed system에서 ML 모델을 잘 돌리기 위한 parallelization technique들도 많이 등장

예전에는 CPU-GPU heterogeneous system이 왼쪽처럼 단순하게 구성되어 있었음. (CPU 쪽에서 통신을 담당)
지금은 HPC/ML에 최적화된 노드 디자인
- intra-node 와 inter-node 통신의 bandwidth와 latency가 상당히 개선되었다
- GPU가 핵심 연산 엔진이기때문에 CPU와 tightly integrate되었고, GPU 간 직접 통신도 가능해졌다 (NIC, high-radix switch)
- GPUDirect RDMA : CPU 없이 GPU 메모리와 NIC 간에 직접 통신이 가능하다
[problem definition]
하지만 현재 app들은 여전히 node 간 통신에서 CPU에 의존하는 경우가 많음, kernel 안이 아니라 kernel boundaries
bulk-synchronous app에서는 다른 독립적인 연산 kernel로 communication을 가릴 수 있고, kernel launch를 여러 번 함으로써 생기는 overhead는 큰 커널을 통해 키울 수 있겠지만 일반적인 상황은 아님
=> 최신 node design을 고려해 intra-kernel communication 을 할 수 있지 않을까??
distributed ML 모델에서 communication은 hide할 수 있는 independent computation이 부족하기에 큰 bottleneck 이다
(ex. weight updates, activation exchange btw layers)
=> independent computation으로는 통신을 숨기기 힘드니까, dependent operation을 fine-grain하게 overlap 해볼까??
[paper's contribution 간단 요약]
collective communication을 가리기 위해 1) 통신과 dependent computation을 fuse하고 overlap 했으며 2) intra-kernel GPU-initiated 네트워크 방식을 사용했다
- 현재 threadblock 단위로, workgroup 단위로 partitioning하는 gpu application에 적용하기 쉽고, hw는 건드릴 필요가 없다
- persistent하게 GPU에 올라가있는 kernel을 두고, 그 안에 logical WG(work group)들이 존재하여 연산과 non-blocking communication을 한다
- data의 일부(fragment)가 연산이 완료되면 커널 종료까지 기다리지 않고 즉시 non-blocking nw transaction을 할 수 있도록 스케쥴링 했다
또한 inter-node 의 경우 zero-copy fused kernels을 도입하여 중간 버퍼링과 copy 연산을 제거하였다
fused kernel의 세가지 prototype을 제시했다
- embedding pooling + All Reduce (DLRM, DL Recommendation Model 에서 볼 수 있는 collective bottleneck)
- GEMV + All Reduce (Transformer 에서 볼 수 있는 collective bottleneck)
- GEMM + All-to-All (MoE 에서 볼 수 잇는 collective bottleneck)
그리고 엔지니어링적인 기여도 충분하다
- PyTorch에 새로운 fused communication-computation kernel 연산자를 추가했다
- Triton에 communication primitive에 대한 wrapper를 제공하여 통신을 고려해 custom fused kernel을 만들 수 있게 하였다
Background
[GPU-initiated intra-kernel communication]

HPC/ML에 맞게 디자인된 최신 system에서는 RDMA(Remote Direct Memory Access)를 사용하면 GPU와 NIC 간의 직접적인 데이터 전송이 가능하다 = bypass CPU
Vendor-specific GPU libraries (e.g., NVSHMEM, ROC SHMEM, MSCCL++)를 통해 intra-kernel 에서 GPU thread가 NIC, peer GPU와 직접 통신을 할 수 있다
----
하지만, 아직 많은 앱들이 왼쪽처럼 kernel boundary에서, CPU에 의해 communication을 하고 있다
computation kernel 전체가 끝나고 나서야 remote 통신이 트리거된다
- 통신을 overlap하기 위해 double-buffering, gpu stream 을 통해 독립적인 작업을 parallel하게 수행할 수 있음
- 독립적인 작업이 없으면 ? several independent kernel이 되도록 더 잘게 쪼개거나..
----
=> GPU-initiated intra-kernel communication을 하면 한 kernel 안에서 fine-grain하게 overlap을 할 수 있다
[DLRM - Embedding Ops + All-to-All]

DLRM 특징
- continous input과 discrete input이 주어진다
- continuous input에 대해 bottom mlp를 통과시켜 고정 크기 contiuous feature를 획득한다
- multi-hot vector(discrete input)가 주어지면 embedding 테이블에서 embedding을 찾아 pooling (mean, sum 등)을 하여 고정 크기 categorical feature를 획득한다
- 이 때 embedding table은 distributed 되어있다, model-parallelism (node0에 emb dim 0~3, node1에 emb dim 4~7 등등)
- model parallelism 방식에서 data-parallelism 방식으로 switch 되기 위해 all-to-all collective 연산이 필요하다 = full batch의 partial embedding만 가지고 있다가 → local batch에 대한 full embedding을 가지고 있도록 해야 함
- continous feature와 categorical feature를 합쳐 top MLP에 통과시킨다
intra-node의 all-to-all 통신이 latency의 상당 부분을 차지하나, 이것과 overlap할만한 독립적인 연산은 bottom mlp밖에 없음
hide할만큼 크지 않음, 즉 embedding pooling 또는 top mlp 같이 독립적이지 않은 연산과 overlap을 해야 한다
[Transformer - GEMV + AllReduce]
transformer는 attention layer + feed forward layer 조합으로 구성된다, 추론 과정은 두 단계로 이루어진다
1) prompt (pre-fill) phase
- 프롬프트 전체를 encoder에 통과시킨다 (cross-attention KV cache)
- 프롬프트 전체를 shift-right된 형태로(맨 앞에 시작 토큰 append) decoder에 통과시킨다 (self-attention KV cache)
=> matrix-matrix multiplication (cf. train도 gemm)
2) token (decode) phase
- 반복적으로 1개의 토큰을 생성한다
=> matrix-vector multiplication

Megatron-LM에서 제시된 FF layer의 model parallelism 방식이다
input duplication + column-wise partition + row-wise partition + partial output reduction (AllReduce)
- token generation 단계에서는 GEMV들이 연이어 일어나고, FF layer에서 partial 결과를 all reduce로 합치는 결과가 반복
- 독립적인 연산이 없기 때문에 allreduce collective는 앞선 gemv 연산과 overlap이 되어야 한다
[Mixture of Experts - GEMM + All-to-All]

MoE 아키텍쳐는 expert라고 불리는 여러 parallel sub-layer를 도입했다
expert는 주로 feed-forward layer로 GEMM kernel이다
각 gpu의 local batch가 gate function을 통과하면, topk sampling을 통해 각각을 상위 k개의 expert(subset of expert)에 복제하여 보냄 => input을 여러 experts에 distribute 하는 all-to-all dispatch scheme
expert를 통과한 뒤 그 결과를 다시 왔던 gpu로 보내어 가중합을 진행함 => all-to-all combine scheme
이런 all-to-all collective가 마찬가지로 상당한 bottleneck이다
따라서 그 앞의 dependent한 GEMM 연산과 All-to-All collective를 fuse해야 한다
Scale Out (intra-node) - Fused Embedding + All-to-All operator
intra-kernel 통신과 node간 communication을 위해 ROC_SHMEM 라이브러리 사용
- 각 GPU에다가 symmetric heap (pinned memory, 각 GPU의 host thread가 동일 크기/주소로 매핑된 힙을 가짐) 할당
- symmetric heap에 메모리 할당하면 NIC에 등록되고, GPU buffer 간 direct 이동이 가능하다
persistent kernel(WG) - logical WG 계층적 구조
- input 형태에 무관한 고정된 grid size를 처리하는 long-running kernel(=persistent WG)를 둔다
- persistent WG라는 긴 커널을 한 번 GPU에 올려두고 내부에서 반복적으로 task를 수행한다 => 이때의 task = logical WG
- logical WG(one iteration) = EmbeddingBag_updateOutputKernel_sum_mean 커널 동작에 대응된다 = 여러 임베딩을 가져와서 sum 또는 mean 같은 pooling operation을 진행
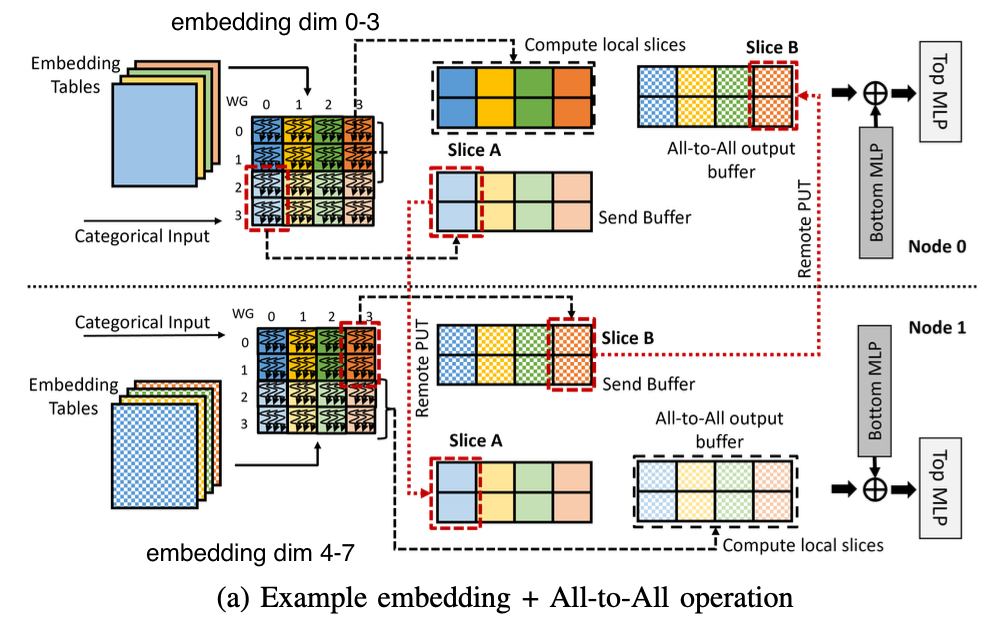
(상황)
- node0에 embedding table 4개가 있다 (input dim 0-3 담당), node1에도 4개의 table이 있다 (input dim 4-7 담당)
- batch size 4의 input이 각 node에 duplicate되어 주어졌다, 4개의 input에 대해 0~3 / 4~7 dim을 계산할 수 있을 것
- send buffer(2x4)와 output buffer(2x8)를 둔다
node0에서
- persistent kernel(WG) 2개가 존재한다, 즉 slice size는 2x1=2 일 것이다
- persistent WG0은 (logical) WG20 → WG23 순서대로 수행한다, 이들은 send buffer에 저장되며 노드 1으로 보낼 것들이다, 그 후 WG00 → WG03 순서대로 수행한다, 이들은 output buffer에 locally store할 것이다
- persistent WG1은 (logical) WG30 → WG33 순서대로 수행한다, 이들은 send buffer에 저장되며 노드 1으로 보낼 것들이다, 그 후 WG10 → WG13 순서대로 수행한다, 이들은 output buffer에 locally store할 것이다
- 다른 노드로의 전송은 slice 단위로 이루어진다, persistent WG0에 의해 WG20이 수행되고 persistent WG1에 의해 WG30이 수행되면 send buffer의 slice A는 persistent WG1에 의해 다른 노드로 전송된다
node1은 비슷하지만 다르다, 위 절반이 보내질 것들이고 아래 절반은 locally store될 것들이다
- persistent kernel(WG) 2개가 존재한다, 즉 slice size는 2x1=2 일 것이다
- persistent WG0은 (logical) WG00 → WG03 순서대로 수행한다, 이들은 send buffer에 저장되며 노드 0으로 보낼 것들이다, 그 후 WG20 → WG23 순서대로 수행한다, 이들은 output buffer에 locally store할 것이다
- persistent WG1은 (logical) WG10 → WG13 순서대로 수행한다, 이들은 send buffer에 저장되며 노드 0으로 보낼 것들이다, 그 후 WG30 → WG33 순서대로 수행한다, 이들은 output buffer에 locally store할 것이다
- 다른 노드로의 전송은 slice 단위로 이루어진다, persistent WG0에 의해 WG03이 수행되고 persistent WG1에 의해 WG13이 수행되면 send buffer의 slice B는 persistent WG1에 의해 다른 노드로 전송된다
최종적으로 각 node에서의 output shape은 {local batch size, (전체 table 수 * 한 table이 담당하는 embedding dim)} 이다.

위에서 말한 timeline을 visualize한 것이다.
book-keeping flag가 두 종류 필요하다
1) WG Done bitmask per slice
한 슬라이스 내의 모든 logical WG들이 종료되어야 communication을 initiate할 수 있다, 따라서 bitmask로 completion status 관리
2) sliceRdy flag per slice
각 slice별로 사용할 준비가 되었음을 알아야 한다.
자기가 처리해 locally store하는 slice는 전부 처리된 경우 ready 상태로 바꾸고
다른 노드로부터 받아야 할 slice는 송신한 쪽에서 sliceRdy 플래그를 세팅한다, receiver는 polling하며 사용할 수 있기까지를 기다린다
두 가지 특징이 있다
1) communication-aware scheduling
각 persistent WG들은 전송되어야 할 logical WG(task)들을 먼저 처리한다
그래야 slice done 후 발생하는 remote communication을 locally store할 logical WG 연산과 overlap 할 수 있으니까
2) synchronization
원래는 한 slice 내의 모든 WG가 done 될 때까지 block하고 synchronize한 뒤에 보내야 했다
하지만 bitmask를 유지함으로써 synchronize 없이 bitmask만 세팅 / (모든 bit가 세팅되었는지) 확인하여 이 slice가 끝났고 전송되어야 하는지 확인한다
참고로 slice를 마지막에 완성하는 persistent WG에서 PUT call을 issue한다
첫 번째는 slice data를 이동하는 요청이고 → barrier를 쳐서 이동 완료를 보장하고 → sliceRdy flag를 상대 노드에 적는 두번째 요청
(차이!!)
기존 방식은 GPU embedding pooling(computation) -> all-to-all (blocking)
이 방식은 slice 별로 embedding ops 끝나는대로 issue PUT, 다른 WG가 계속 연산을 돌리고 있음
Scale Up (inter-node) - Fused GEMV + AllReduce operator
remote GPU는 RDMA를 필요로 하지만, 단일 노드 내 gpu들은 NVLink나 Infinity Fabric 연결을 통해 다이렉트로 읽고 쓸 수 있음
따라서 중간 버퍼+copy 없이 그냥 peer gpu memory에 바로 쓰면 됨
GPU가 N개 있고, output이 (GEMV니까) Mx1 형태라고 하자
그러면 각 GPU가 M/N 개의 output tile을 담당하여 reduce하고 = reduce scatter (최종 reduce된 값을 여러 gpu가 나눠서 가짐)
reduced된 결과를 여러 gpu들로 broadcast하여 모두가 동일한 final output 가지도록 함 = all gather
각 gpu는 reduction buffer가 필요 (M/N(각 gpu의 계산값) * N(gpu 개수) 크기) => row-wise reduce 하면 최종 결과가 나옴

위 그림에서 node 0에
- persistent kernel(WG)가 두 개 존재한다고 해보자
- persistent WG0은 2번째 tile을 계산하고 node1의 reduction buffer에 저장한다, 상대 노드에 다 저장했다는 ready flag를 세팅한다, 0번째 tile을 계산하고 local reduction buffer에 저장한다
- persistent WG1은 3번째 tile을 계산하고 node1의 reduction buffer에 저장한다, 상대 노드에 다 저장했다는 ready flag를 세팅한다, 1번째 tile을 계산하고 local reduction buffer에 저장한다
node1 에서는 반대이다 (오히려 0,1번째 tile을 보내고 2,3번째 tile을 저장)
- persistent WG0은 0번째 tile을 계산하고 node0의 reduction buffer에 저장한다, 상대 노드에 다 저장했다는 ready flag를 세팅한다, 2번째 tile을 계산하고 local reduction buffer에 저장한다
- persistent WG1은 1번째 tile을 계산하고 node1의 reduction buffer에 저장한다, 상대 노드에 다 저장했다는 ready flag를 세팅한다, 3번째 tile을 계산하고 local reduction buffer에 저장한다
node 0에서
- persistent WG0은 ready를 polling하고 있다가 세팅되면 0번째 tile에 대해 reduction을 수행해 최종 결과 확보
- persistent WG1은 ready를 polling하고 있다가 세팅되면 1번째 tile에 대해 reduction을 수행해 최종 결과 확보
node 1에서
- persistent WG0은 ready를 polling하고 있다가 세팅되면 2번째 tile에 대해 reduction을 수행해 최종 결과 확보
- persistent WG1은 ready를 polling하고 있다가 세팅되면 3번째 tile에 대해 reduction을 수행해 최종 결과 확보

timeline을 시각화하면 다음과 같다
즉 각 tile을 persistent WG가 나눠서 처리하는데, 반은 자신이 처리하고 반은 보내는 느낌
flag는 단 한개만 필요하다
1) bitmask는 필요 없다
- single thread (persistent WG)에서 network communication을 initiate할 필요 없다
- 모든 thread가 WG 내에서 다른 gpu의 목적지 버퍼에 다이렉트로 쓸 수 있다
2) done flag 한 개만 필요하다
- WG 내의 모든 remote write가 끝나면 done임을 나타내는 ready flag만 세팅하면 된다
- 그리고 local write를 하는 작업을 이어서 한 뒤, peer WG가 remote write을 끝냈는지 polling으로 기다리고, 그 후 reduction buffer를 reduce하고 그 결과를 broadcast 하면 된다
(차이!!)
기존에는 gemv 계산 (computation) → all reduce 순서였다
얘는 각 tile 별로 계산하자마자 peer gpu memory store(communication) = 계산과 쓰기 작업이 interleave
cf) inter-node 에서의 GEMM + All-to-All 연산은?
비슷하다! 대신 마지막에 reduction + broadcast reduced result 부분이 빠지면 되겠지
all-to-all은 단순히 재배치(이어붙이기 등)만 하는거니까
Overhead Issue
* API Latency
- kernel 안에서(GPU thread 안에서) network transaction을 시작하는 오버헤드도 분명이 존재한다
- 하지만 slice 이동, book-keeping operation 뿐이기에 ok
* Occupancy
- ROC_SHMEM API call 호출은 gpu register를 차지한다
- 이때문에 fused kernel 호출 시 기존 pytorch 구현 대비 12.5% 낮은 occupancy를 보이지만 최종 성능은 더 좋다
* Inter-WG Synchronization
- slice가 완료되었는지 persistent WG 간의 동기화는 bitmask로 진행된다
- barrier 필요 없이 cross-lane operation을 활용해 여러 warp 간 bitmask를 세팅하고, 전부 세팅되었는지 효율적으로 체크
ML Framework Integrations
* PyTorch에 연산자를 추가함
- device memory에 symmetric heap 추가하는 api
- cpu host mem의 텐서를 할당된 device mem으로 옮기는 api
- fused kernel operation 관련 api (ex. torch.embeddingAll2AllOp)
- can be automated using existing graph transformation optimizations within ML frameworks
* Triton Framework 확장
- python-like 문법으로 gpu 커널을 작성할 수 있게 해주는 오픈소스 컴파일러/런타임
- C/C++ CUDA 커널을 짜는 대신 python에서 곧바로 gpu 코드를 쓸 수 있음
- 기존 triton은 당연히 gpu내 계산 (gemm, embedding lookup 등등)만 지원
- communication primitive 또한 처리할 수 있게 확장했음: ROC_SHMEM 이나 scale-up communication에 대한 wrapper 추가
Evaluation
* 기본 세팅

- Embedding + All-to-All : 32 logical WGs for an output slice, embedding_dim = 256, global batch와 per gpu의 embedding table 개수를 조정해가며 테스트함, large scale-out simulation에 대해서는 실제 DLRM application을 사용함
- GEMV + AllReduce : inference에 해당되는 문제, 따라서 scale-up 상황에서 테스트, small size에선 오히려 kernel launch overhead가 커질 것이므로 bulk-synchronous RCCL-based 베이스라인으로 비교
- GEMM + All-to-All : Tritron GEMM 구현에다가 All-to-All 구현을 추가하여 비교
(simulation & real hw 두 케이스에서 모두 테스트 진행)
scale-up evaluation (single node, 4 gpus)
<Embedding + All-to-All>

- baseline에 비교했을 때 small batch에서는 all-to-all latency가 크지 않아 개선 효과가 미미했지만
- large batch에서는 total runtime이 크게 줄었다
<GEMV + AllReduce>

- larger input에서의 성능 개선이 적더라, output vector size가 커질수록 infinity fabric link의 contention이 늘어 혜택이 감소함
- 작은 input size에서는 22%까지의 runtime 감소도 있다
<GEMM + All-to-All>

- 개선 효과가 그리 크진 않다, 왜냐면 triton의 generic gemm implementation에다가 all-to-all을 fuse 했기 때문에 GEMM 연산이 대부분의 실행 시간을 차지한다
large scale-out evaluation (simulation, 128 nodes and one GPU each)

- 실제로 fused kernel에서는 embedding operation을 대부분 숨길 수 있었다
Inter-node evaluation : WG profiling

slice 16, 32개의 persistent WGs의 execution time을 프로파일링한 결과
- WG15 와 WG31을 보면 communication-aware scheduling을 확인할 수 있다 => PUT issue 후에 local completion
- 어떤 WG는 fused kernel computation이 끝나고 data를 기다리는데 다른 WG는 아직 compute 중인 시간도 있음 => communication-computation overlap !!
- WG15와 WG31이 아마 대부분의 communication을 issue할 것, 왜냐면 한 slice의 마지막 logical WG를 처리할 가능성이 높기 때문, 따라서 이들의 kernel computation time이 대부분이다
- data를 기다리는 시간도 WG마다 다른게 서로 다른 sliceRdy flag에 대해 polling하고 있기 때문
Inter-node evaluation : Execution time

- embedding + all-to-all fused kernel이다 (slice size 32)
- smaller batch size에서는 fully overlap한 것보다 오히려 더 좋더라 = 기존 방식은 작은 배치땜에 underutilization
Inter-node evaluation : Occupancy effect

- gpu-initiated network op 때문에 gpu occupancy가 떨어지는 현상이 있었다
- 근데 occupancy loss는 성능을 떨어뜨리지 않는다, 오히려 occupancy가 너무 높으면 memory contention 때문에 parallelism의 효과를 충분히 누리지 못하더라
Inter-node evaluation : Communication-aware Scheduling

communication-aware한 방식으로 WG를 schedule해야될 필요성을 보여준다
초록색/파란색: remote communication할 것들을 먼저 처리 -> 그 뒤에 locally store할 것들을 처리, 실제 PUT issue하는 node 1의 실행시간이 0에 비해 dramatic하게 길지 않음
빨간색/노란색: communication aware하지 않게 그냥 순차적으로 처리하면 통신과 local computation을 overlap하지 못해 node 1의 실행시간이 지나치게 길어짐 => skewed execution time
즉 요약하자면
CPU-initiated networking + kernel-boundary communication → gpu initiated networking + intra-kernel communication
RDMA + communication-aware scheduling + zero-copy fused kernel
provide fused kernel prototype = fused embedding + All-to-All, GEMV + AllReduce and GEMM + All-to-All kernels
new PyTorch operators + exteded Triton framework Extension
정교하게 overlap을 했고, evaluation 또한 빈틈 없을 정도로 분석적인 논문이라 생각함