problem of original transformer architecture
현재 대부분의 LLM은 autoregressive Transformer model에 기반을 둔다. 하지만 이 Transformer 기반의 sequential한 연산은 memory-bound하다 (DNN, CNN의 경우 conv 연산이나 GEMM 연산 때문에 compute-bound인 경우가 많음).

위 사진에서 회색 부분은 model weight이고(serving 단계에서는 static하게 load되어 있음), 핑크색 부분은 attention mechanism에서 필요한 key와 value tensor를 저장하는 KV cache이다(request에 따라 dynamic하게 바뀜). 기타 부분은 activation 같은 임시 tensor이다. dynamic하게 바뀌는 KV cache memory가 memory-bound의 주된 이유이다.
기존 방식은 KV cache of request를 연속된 메모리 공간에 단순히 저장해둔다. 하지만 이들은 input에 따라 grow/shrink하고 언제 free되어야할지도 다르다. 즉 lifetime 및 length를 사전에 알 수 없다.
1) 그래서 continuous mem space에 pre-allocate 해둔다 => internal & external mem fragmentation, pre-allocation 때문에 다른 shorter request가 메모리를 fully utilize하지 못한다
2) memory sharing이 효율적이지 못하다 => beam search, parallel sampling을 할 때 매번 copy가 필요하다
OS는 virtual memory scheme을 통해 메모리를 관리하여, logically continuous space더라도 physically하게는 discrete하게 저장한다. 이런 virtual memory with paging에서 아이디어를 얻은 PageAttention을 제시한다
= request의 KV cache를 block 단위로 나누고 (B tokens in each block), block 단위로 메모리에 저장한다
= same sized block으로 external fragmentation을 없애고 작은 block size로 internal fragmentation을 줄인다
= memory sharing이 용이하다. 단순히 mapping table에서 same physical block을 가리키게 하면 될 것.
이런 PageAttention 기법을 적용해 vllm을 만들었다
* block-level memory management 를 적용하고
* preemptive request scheduling (recomputation or paging to cpu)를 적용하였고
* GPT, OPT, LLaMA 같은 유명 LLM의 다양한 size 모델들의 serving을 지원한다
So, what's KV cache and why it's a problem?
transformer model의 추론(serving)은 주어진 prompt(context)를 처리하고, [BOS] 같은 시작토큰부터 추가 토큰을 하나씩 samping해나가는 autoregressive 방식이다. 이러한 attention 연산을 위해 초기 프롬프트와 이미 생성된 토큰들에 대한 key-value 값이 필요하며 이들을 KV cache로 저장해두어 매 토큰 생성 시 불필요한 recomputation을 피한다. 하지만 저장 공간이 많이 필요하다는 tradeoff가 존재한다
* query는 매 step의 입력 토큰 임베딩으로 계산되고, 과거 정보를 담은 KV cache와의 attention 연산을 통해 다음 토큰에 대한 확률 분포 구한다 => 새롭게 생성된 토큰에 대해서 각 layer에서의 key value가 계산되고, 기존 캐시에 append 된다
OPT-30B model이 있고, seq_len = 1024, batch_size = 128, num_layers = 48 이라고 하자.
* KV cache에 필요한 메모리는 128(batch_size) * 2(K, V) * 48(num_layers) * 7168(d_model = num_head * head_dim) * 1024(seq_len) * 2B = 180GB 이다
* 토큰마다 우리가 새롭게 저장하는 bytes는 2(K, V) * 48(num_layers) * 7168(num_head * head_dim) * 2B 일것이다
* 30B 모델이므로 실질적인 파라미터는 30GB * 2 = 60GB 일텐데, 무려 3배의 용량을 차지한다는 것이다
=> transformer의 inference는 memory-bound한 연산이다 !!
KV cache는 새로운 토큰이 생성될 때마다 grow하고
context 길이 제한 시 sliding window로 잘리기도 하고, 추론이 끝나면 메모리가 회수되고, beam search에서 불필요한 빔을 제거하는 등의 경우에 shrink한다
Background
* transformer-based large language models
* autoregressive generation (한 토큰씩 생성), key와 value vector는 이후 토큰 생성을 위해 KV cache로 저장된다
- prompt phase: 전체 user prompt가 한 번에 input으로 주어지고, parallelize를 통해 GPU를 효율적으로 사용할 수 있다
- autoregressive generation phase: x_n+t 토큰을 input으로 받아 x_n+t+1 토큰의 probability를 구한다, position 1 ~ n+t-1 의 key와 value 벡터는 캐시되어있다, matrix-vector multiplication이라 덜 효율적이고 dependency 때문에 병렬화 제약이 있다 => memory-bound
* batching for LLM
- request가 서로 다른 시간에 올 수 있다는 단점 => iteration level로 operate함으로써 완료된 요청은 다른 요청으로 갈아끼우는 방식으로 queueing delay 없앨 수 있음
- input과 output length가 다를 수 있다는 단점 => ㅠㅠ
Memory Problem in previous LLM Serving
fine-grained batching을 통해 computing을 효과적으로 할 수 있었지만 KV cache 때문에 memory-bound였다
KV cache는 2(key&value) * hidden state size * num layers * 2 (Bytes per FP16) 이니까 엄청 크다
=> OPT의 sequence 길이는 2048인데, 한 request당 1.6GB의 KV cache가 요구되므로 batch에 요청 몇십개가 한계

기존 시스템에서는 위와 같이 request의 가능한 최대 시퀀스 길이에 기반하여 정적으로 allocate했다
- maximum fixed size로 할당하니 internal fragmentation 문제가 있었고
- memory allocator가 할당하다 external fragmentation이 생기기도 하고
- future token을 위한 reserved slots은 최종적으로 쓰이긴 하지만 다른 request가 사용하지 못하게 길게 hold할수도 있다
물론 fragmented part를 합치는 compaction 같은 기법을 적용할 수 있지만, performance가 중요한 serving에서는 부적합
PagedAttention & KV Cache Manager
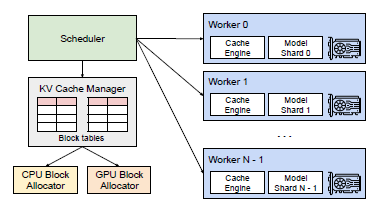
centralized된 KV cache manager를 두고, 얘가 block table을 유지하면서 logical - physical 매핑을 관리한다. 각 GPU worker에서 block engine이 있어 GPU DRAM을 fixed size로 쪼갠다. 이후 들어오는 KV cache 또한 KV blocks로 나누어 재구성한다.
- 여러 요청이 들어왔을 때 FCFS 규칙에 따라 처리한다
- 만약 physical block이 전부 채워져서 evict할 때 all-or-nothing을 적용한다, 한 sequence의 모든 블록 단위로 evict 하거나 reschedule한다 (왜냐면 시퀀스 단위로 공유되거나 사용되기 때문)
- reschedule 시엔 1) CPU memory에 swap해두거나 2) 그냥 없앤다음 단순히 recompute 한다


Paged Attention은 블록 단위로 계산한다. 각 블록은 B개의 key 또는 value 토큰을 담고 있고, attention computation은 위 식으로 계산된다. query i와 j번째 block의 key들 간의 attention score를 계산한다. B개씩 블록 단위로 계산
How does PagedAttention work

- 초반에는 prompt computation에서 필요한 만큼의 KV block만 reserve한다
- pagedattention 메커니즘을 통해 first autoregressive generation phase 진행, 마지막 logical block에 대해 꽉 차있지 않으면 거기 추가, second decoding phase에서는 새로운 KV block을 할당하고 거기다가 추가
- block 내의 여러 토큰 연산을 parallel하게 할 수 있음, 오른쪽처럼 서로 다른 sequence를 동시에 처리할 수도 있음
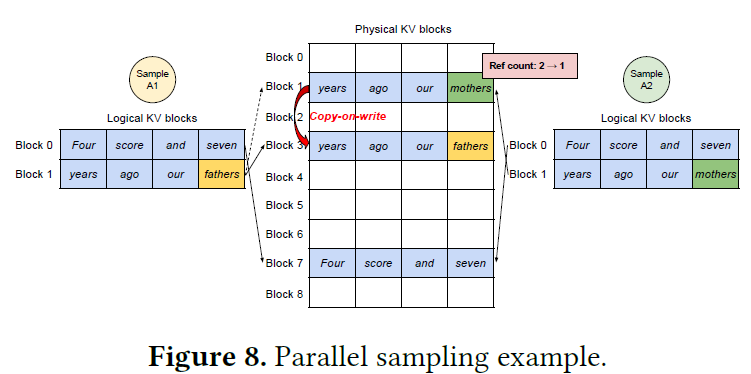
- parallel sampling도 용이하다, 긴 input prompt에 대해 메모리 절약을 상당히 할 수 있음
- 각 kv block에 대한 reference count를 관리하여 여러 output sample이 참조하고 있음을 확인
- 만약 새로운 output token을 추가하려하는데 refcnt>1 이면 copy-on-write 후 refcnt--
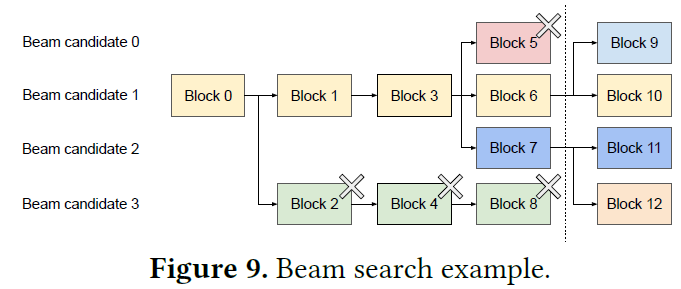
- beam search시 candidate 간의 동일한 output을 가지는 경우 단순히 refcnt만 증가시킨 후 메모리를 공유하면 됨
- 기존 system에서는 beam candidate간의 memory copy가 필수였으나, 이런 게 사라짐
- 각 beam candidate 간의 분기하는 지점에서 copy-on-write를 적용해주기만 하면 됨
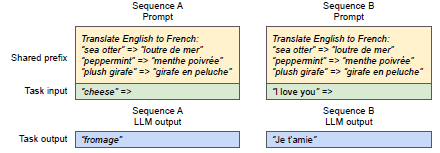
- shared prefix의 경우에도 prefix prompt에 대한 KV cache를 share할 수 있으므로 유리하다
Implementation Detail
kernel optimization
- KV cache를 block으로 쪼개어 저장하는 과정에서 reshape + write fusion
- block read와 paged attention fusion, warp 단위로 같은 block 읽게 고려
- block copy operation을 batching하여 하나의 kernel launch로 처리
various decoding algorithms
- fork, append, free
Evaluation
Workload는 SharedGPT(gpt와의 대화 데이터, input 및 output이 더 길다), Alpaca(gpt의 self-instruct data)
request arrival time은 Poisson distribution으로 설정
비교 대상은
1) FasterTransformer (latency optimized) + dynamic batching을 위한 스케쥴러 추가
2) Orca + 3 version (output 길이를 완전히 아는 oracle, 2의 배수 단위로 근사한 pow2, 항상 최대를 reserve하는 max)
key matrix는 normalized latency
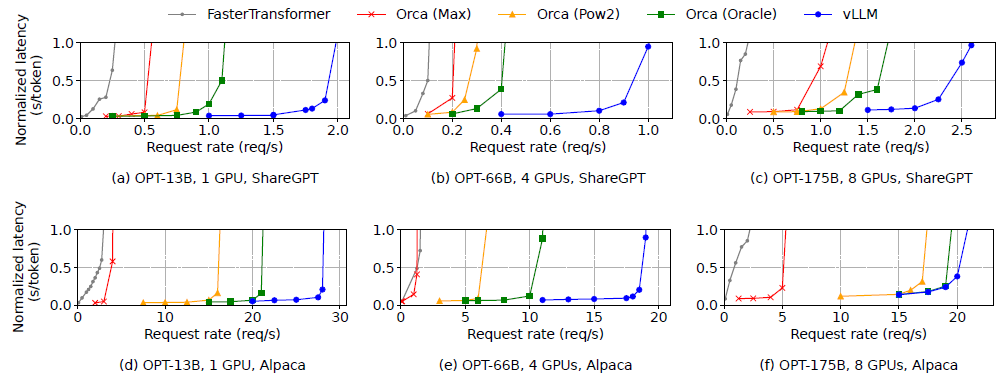
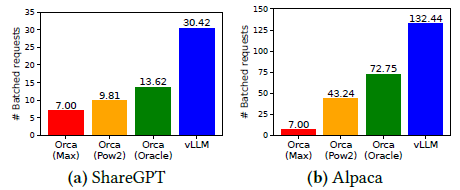
- vLLM의 효율적인 메모리 관리 때문에 더 높은 request rate까지 버틸 수 있다, 더 많은 batching을 통해 처리하더라
- (f)에선 거의 차이가 없던데 실험 환경 상 GPU 메모리가 무척 컸고, 데이터셋의 sequence 길이 또한 짧아서 다른 모델에서도 batching 가능
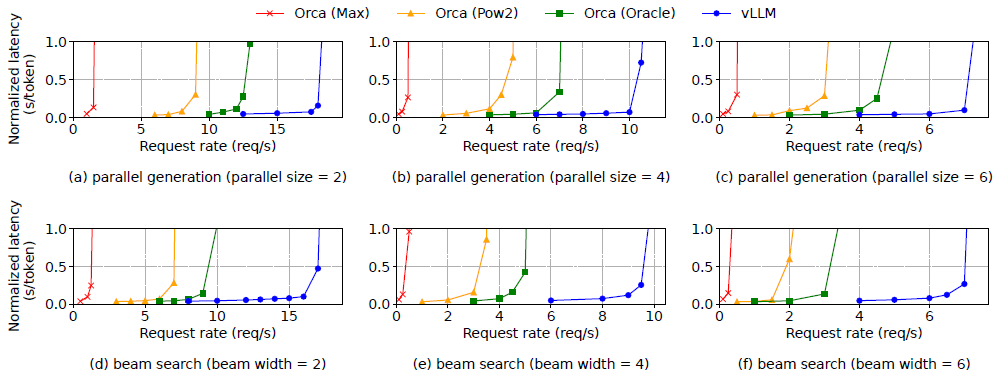
- parallel sampling과 beam search 에서도 우수하다
- chatbot workload와 prefix prompt workload 에서도 우수한 특성을 보이더라
Ablation Study
Q. GPU kernel launch 때문에 오버헤드가 크지 않냐?
-> 물론 block table access, do some branch logic, handle variable seq length 를 위한 GPU kernel의 오버헤드가 있긴 하지만, attention behavior에만 국한된 것이고 시스템 전체 관점에선 퍼포먼스가 더 좋다
Q. KV block size는 어느 정도가 적당?
-> workload의 특성에 다라 다르겠지만 16 정도면 internal fragmentation을 피하면서 GPU를 효율적으로 사용하기 충분
Q. rescheduling 기법 중 recomputation vs. swapping?
-> 작은 블록 사이즈에 대해서는 recomputation이 더 우수하다 (작은 블록은 CPU-GPU PCIe bandwidth를 비효율적으로 사용하므로), 대신 큰 블록 사이즈에 대해서 swapping이 엄청 우수해지는 건 아니다 (20% 이내)
Discussion
1) 모든 GPU workload에 대해 동작하진 않을 것이다
- DNN 학습은 tensor size가 고정되어있다, 미리 optimization technique 적용할 수 있다
- DNN serving은 compute bound이다, 따라서 이런 추가적인 작업이 overhead만 추가할 수 있다
2) OS와의 다른 점
- all-or-nothing eviction & scheduling , recomputation method