https://distill.pub/2021/gnn-intro/
A Gentle Introduction to Graph Neural Networks
What components are needed for building learning algorithms that leverage the structure and properties of graphs?
distill.pub
What's graph?

- each node, edge, global information은 임베딩 형태로, 고차원 텐서 형태로 저장되어 있다
- directed, undirected 두 종류의 edge가 있다
Graph Examples in the wild


- 분자 구조: atom이 vertex, bond가 edge에 대응됨
- social network
- citation network
- cv에서 한 씬에서 object들과 그들의 관계, programming code, 수학적 수식 등도 graph로 파싱할 수 있음
Task in graph-valued data

1) graph level task: graph 전체에 대한 하나의 property를 예측한다 (ex. 분자 구조가 주어졌을 때 이들의 냄새가 어떤지)
2) node level task (ex. given node가 어느 집단에 속해있는지)
3) edge level task: (ex. image scene understanding, 이미지에서 인지한 object들 간의 관계를 파악하여 이해)
하지만 이런 task들을 푸는데 어려움이 있다, why?

1) 데이터 형식의 차이
- ML model은 일반적으로 정사각 형태의 (ex. image), grid-like array를 input으로 받는다
- graph에서는 4개의 information이 존재한다 : node, edge, global-context, connectivity
2) connectivity 표현의 어려움
- adjacency matrix가 가장 쉬운 선택
- 하지만 very sparse하고, 따라서 공간 사용이 무척 비효율적이다
- permutation invariant 하지 않다, 동일한 graph topology를 서로 다른 형태의 인접 행렬로 표현 가능하다..
- 하나의 방법은 adjacency list를 관리하는 것, n_node^2 가 아닌 n^edge의 공간만 차지 / CSR 포맷 등등?
Graph Neural Network
permutation invariance 성질을 유지하면서 graph의 특징들(node, edge, global context)을 변환하는 기법
- "graph-in, graph-out" 아키텍쳐 => 그래프의 node/ege/global-context info가 인풋으로 주어진다
- "message passing" 방식의 신경망 네트워크
1) simplest GNN (pooling at last)

- MLP (혹은 미분 가능한 다른 모델)을 적용하자, 어떤 objective function을 정해두고 backprop을 수행하여 node/edge/global에 대한 layer 들을 학습하자
- 여기서의 layer는 graph와는 independent하다
- graph의 connectivity랑 # of feature vector 등은 유지되겠지
1-1) how to predict?
pooling process를 통해 information을 수집한다: gather embedding -> aggregate embeddings

- final layer에 edge-level embedding만 있다면, 이 info를 pooling한 후 linear classifier 를 통과시켜 노드를 예측
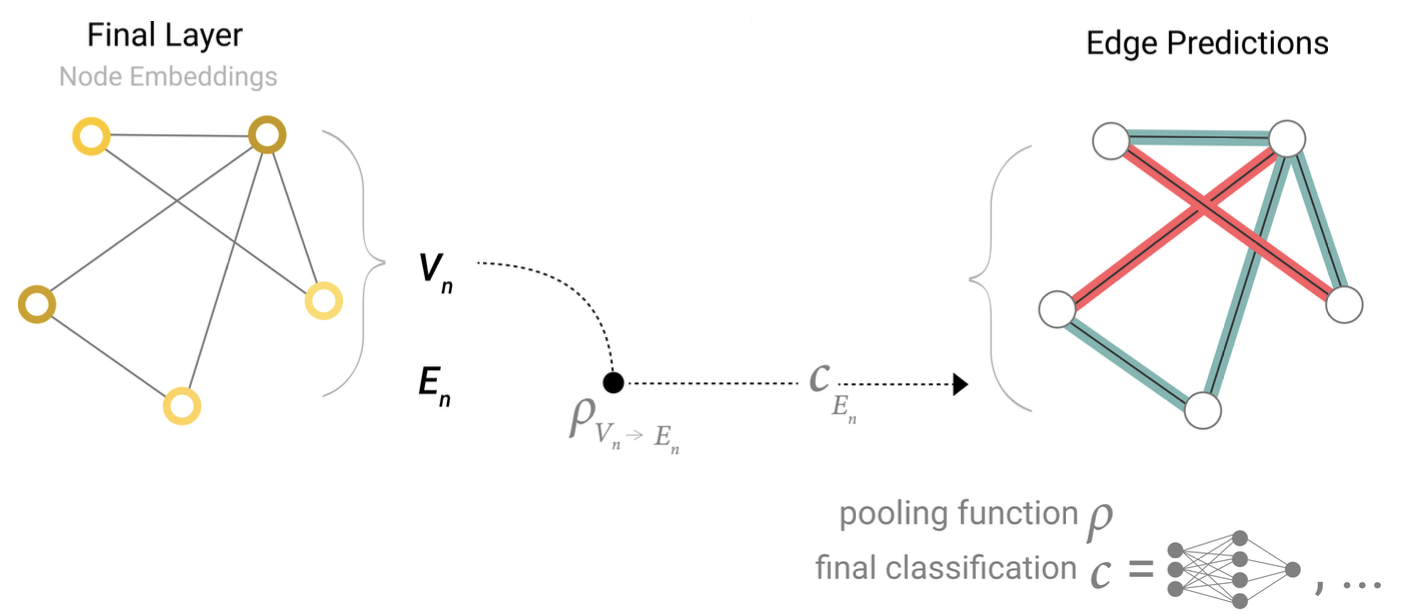
- node-level feature만 있다면, 이 Info를 pooling한 후 linear classifier를 통과시켜 edge를 예측

- 이런 global average pooling 방식도 가능, 가능한 모든 info를 aggregate하여 예측
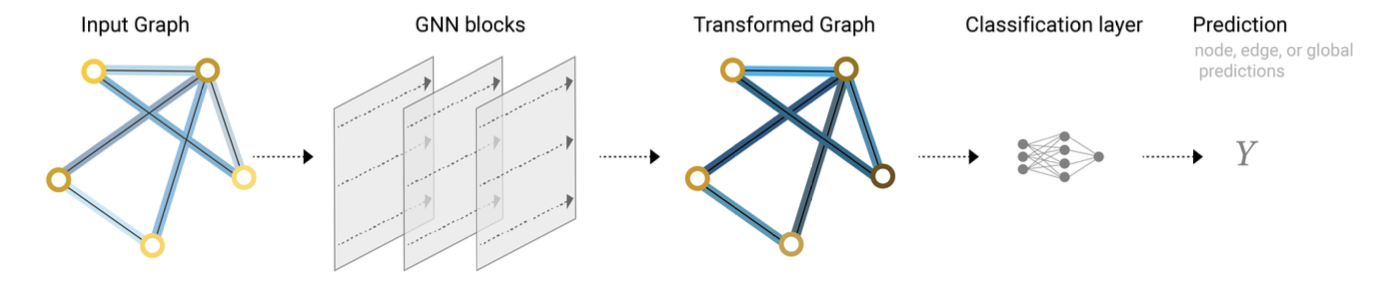
- generalized end-to-end pipeline, connectivity 정보는 pooling 할 때 말고는 쓰지 않는다
- GNN block을 여러개 쌓고, pooling을 통해 attribute 간에 정보를 전달하고, 작업 수행
2) GNN with messages passing btw different parts
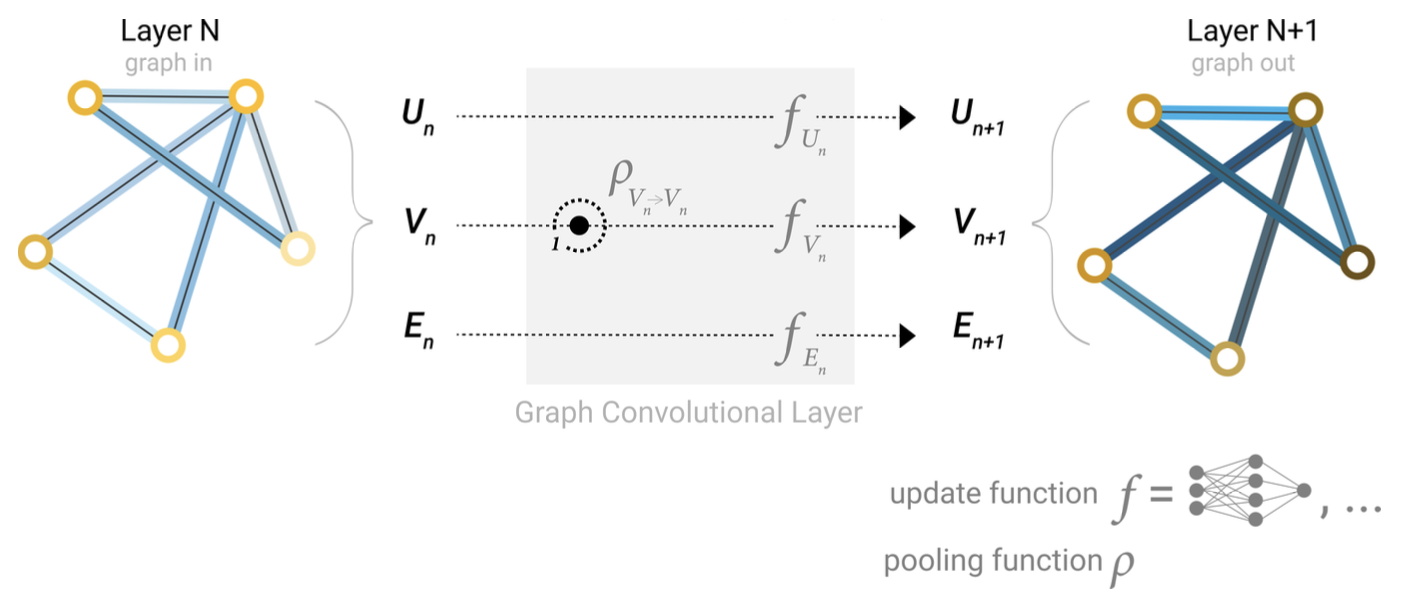
- GNN layer에서도 graph connectivity를 사용할 수 있을 것 => use message passing
- gather all neighboring node's embedding → aggregate → update function 통과 → updated embedding
- convollution과 비슷, 3개의 layer를 통과한다면 각 노드는 3 hop away의 정보까지 반영하고 있겠지

- pooling edge(vertex) information → pass the message to the node(edge) → do update function
* edge/vertex embedding이 same size가 아닐 수 있다 => linear mapping 을 사용할 수도 있음, 그냥 concat 할수도 있고
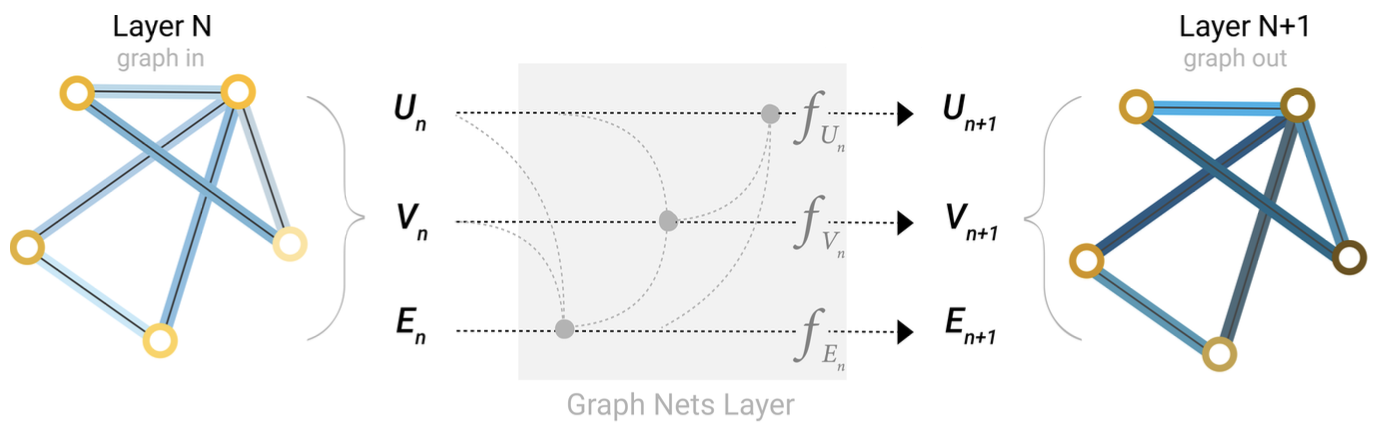
- 멀리 떨어진 node 간에는 정보 전달이 효율적으로 안 될수도 있다
- virtual edge로 해결할 수도 있으나, 멀리 떨어진 노드끼리의 연결을 강제로 만드는 건 computationally expensive
- master node라고도 불리는 global representation(U)를 두고, 이를 layer에서 업데이트할 수 있다
** 어떤 graph attribute을 어떤 순서로 update할지, 어떻게 aggregate할지는 순전히 design choice 이다
** neighborhood-based pooling operation에 기반하지 않은 GNN도 등장하고 있다
Sampling and Batching techniques in GNN
이런 신경망 네트워크를 학습하려면 training data의 일부(mini-batch, constant batch size)에 대해 계산을 한 뒤 gradient 값으로 네트워크의 파라미터를 업데이트하는 게 일반적이다
= larger graph의 필수적인 특징을 보존하는 subgraph를 생성하는 것과 동치이다
하지만 graph는 매우 dynamic한 구조를 가지고 있어 batch size가 constant 하지 않다
또한 sub-selection of nodes and edges가 너무 강력하다면? (분자의 일부 구조만 떼오면 완전히 새로운 분자가 되어버림)

하나의 방법은 node-set에서 랜덤하게 uniform number of node를 샘플링하고, distance k까지의 인접 노드들을 포함하여 subgraph를 구성하는 것이다, loss는 대신 incomplete neighbor를 가진 노드들에 대해서는 mask 하고 계산
sampling은 그래프가 크거나, 메모리 제약이 있는 상황에서 필수적인 기법이다
ex) Cluster-GCN, GraphSaint ..
Inductive Biases in GNN
image model에서는 CNN을 사용하기에 translation invariant한 성질을 가진다, 개의 좌하단 모습을 보던 우상단 모습을 보던 개라고 잘 classify한다
text에서는 RNN을 사용하여 토큰의 순서에 집중한다, 단어의 의미를 파악할 때 맥락이 중요하므로 transformer를 사용해 다른 토큰을 attend한다.
=> data의 성질을 잘 처리할 수 있게 모델을 specialize한다 = inductive biases
그렇다면 graph를 처리하는 모델은
- entities 간의 관계를 잘 보존해야 하고(인접 행렬), graph symmetries를 잘 보존해야 한다 (permutation invarience)
이거를 대응하기 위해
- 각 graph component(edge, node, global)이 서로 어느정도 연관되게 하여 이런 graph structure의 특징을 잘 반영하도록 한다
- relational inductive bias를 가지도록 한다 (서로 연관되게 ...)
Choosing Aggregation Operations
sum, max, mean 등 다양한 op를 쓸 수 있다, 대신 node ordering과 node number에 invariant한 연산이어야 함
mean
- neighbor의 수가 매우 변동적일 때 (높은 분산을 가질 때)
- local neighborhood의 표준화된 feature를 파악하고 싶을 때 유용
max
- local neighborhood에서 하나의 두드러진 feature를 주목하고 싶을 때 유용
sum
- local neighbor의 future distribution을 나타내며, outlier에 주목할 수 있다
- 위 두 장점을 합친 느낌이라 많이 사용됨
How to communicate information btw graph attributes?
graph attribute간 pooling을 하기 위해 message passing을 한다고 했다, 어떤 방법들이 있을까?
1) graph convolution as matrix multiplication
- (graph attribute의 embedding에) adjacency list를 곱한다
- A^k _ij 는 node_i 에서 node_j 까지 k hop에 걸쳐 갈 수 있는 모든 경로를 의미
2) graph attention network

- 1-degree neighboring node들에 대해 weighted sum을 취할 수 있을 것이다
... 더있다
(이것들은 다음 게시물에서 자세히)
GNN simple example
small molecular graph에 대한 graph-level prediction을 한다고 해보자. (does it smells "pungent" or not)
- atom node는 one-hot encoding value를 가지고 있다 (원소에 따라)
- bond edge 또한 one-hot encoding을 가지고 있다 (bond type에 따라)
- 여러 개의 GNN layer를 depth만큼 쌓는다
- update function은 1 layer MLP + relu activation , pooling에는 max/mean/sum 을 사용할 수 있다
emperical analysis

- parameter 수가 많을수록 performance가 높아진다
- GNN은 매우 parameter-efficient model type이다, 어느 정도만 파라미터가 많아져도 준수한 정확도가 나온다
- graph attribute에 대한 embedding dim을 높일수록 평균 성능이 높아지더라
- layer 수가 많아질수록 평균 성능은 높아지는데, peak performance는 도달하지 못했다, representation이 여러 iteration을 거치며 희석되었을 위험이 있음
- aggregation function은 sum, mean, max 모두 비슷하게 좋더라

- graph attribute communication은 없는 것보다 있는 게 좋다, 이 task는 global representation에 치중된 편으로, 명시적으로 이를 중간중간 학습해야 더 좋더라
Other Types of graphs
- multigraphs (multi-edge graphs) : several types of interaction
- hypernode graph : hirerarchical 정보를 나타내기 위해 nested되어있는 graph
- hypergraph : edge가 3개 이상의 노드에 연결
GNN이 무엇인지 대략적으로 알게 됨, 여러 intuition도 들어있어서 꽤 읽기 괜찮은 글이었다
'AI > graph' 카테고리의 다른 글
| GNN에서의 convolution (1) | 2025.04.14 |
|---|