https://github.com/google-research/vision_transformer
GitHub - google-research/vision_transformer
Contribute to google-research/vision_transformer development by creating an account on GitHub.
github.com
Introduction
- Transformer는 그 computational efficiency와 scalability 덕분에 NLP 분야에서의 정론이 되었음
- model과 dataset이 계속 커지고 있음에도 performance saturation이 (아직) 없음
- 이 논문에서는 CNN이 지배중인 computer vision 분야에 Transformer를 도입하고자 함 (기존 아키텍쳐 최소한으로 변경하면서)
- 이미지를 patch로 split하고 linear embedding의 시퀀스를 Transformer의 input으로 주었다
- Transformer는 CNN과 달리 translation equivariance/locality 같은 inductive biases가 부족하다
- 이 때문에 mid-sized dataset에서는 ResNet보다 성능이 떨어짐
- 하지만 충분히 큰 scale에서 pre-train 하고 작은 task에 대해 transfer learning을 했을 때는 성능을 뛰어넘더라
Vision Transformer(ViT) Model

모델의 전체적인 구조이다. standard Transformer 구조를 최대한 따라가려고 하였다.
STEP 1. image를 reshape하고 flatten한다 (+ additional token)
- standard Transformer의 input으로 넣기 위해서는 1D sequence of token embedding으로 변경 필요
- H x W x C dimension의 image를 P*P 패치로 쪼갠 뒤 flatten 하여 N x (P*P*C) dimension으로 reshape (N=HW/P^2)
- embedding filter(학습 가능한 linear projection matrix)를 곱해 각 패치를 latent vector size D로 mapping한다
- patch embedding을 쭉 펼친다음 맨 앞에 learnable embedding x_class를 추가한다 (like BERT's [class] token)
* 이 토큰의 output state는 image representation을 나타냄, pre-training과 fine-tuning 시 여기에 classification head 붙임
* classification head는 MLP with one hidden layer(pre-train) / single layer (fine-tuning)
STEP 2. position embedding을 더한다
- position information을 반영하기 위해 standard learnable 1D position embedding을 더한다 (2D-aware position embedding 보다 emperical하게 더 좋았다고 함)
STEP3. transformer를 통과시킨다
- Layer Norm + Multihead Self Attention + Residual Connection + LN + MLP + Residual Connection 조합의 블록이 L개
- 마지막에 LN을 거쳐 output y를 구한다 (image representation)
class Encoder1DBlock(nn.Module):
"""Transformer encoder layer."""
mlp_dim: int
num_heads: int
dtype: Dtype = jnp.float32
dropout_rate: float = 0.1
attention_dropout_rate: float = 0.1
@nn.compact
def __call__(self, inputs, *, deterministic):
# Attention block.
assert inputs.ndim == 3, f'Expected (batch, seq, hidden) got {inputs.shape}'
x = nn.LayerNorm(dtype=self.dtype)(inputs)
x = nn.MultiHeadDotProductAttention(
dtype=self.dtype,
kernel_init=nn.initializers.xavier_uniform(),
broadcast_dropout=False,
deterministic=deterministic,
dropout_rate=self.attention_dropout_rate,
num_heads=self.num_heads)(
x, x)
x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=deterministic)
x = x + inputs
# MLP block.
y = nn.LayerNorm(dtype=self.dtype)(x)
y = MlpBlock(
mlp_dim=self.mlp_dim, dtype=self.dtype, dropout_rate=self.dropout_rate)(
y, deterministic=deterministic)
return x + yencoder block 코드이다.
if self.add_position_embedding:
x = AddPositionEmbs(
posemb_init=nn.initializers.normal(stddev=0.02), # from BERT.
name='posembed_input')(
x)
x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=not train)
# Input Encoder
for lyr in range(self.num_layers):
x = Encoder1DBlock(
mlp_dim=self.mlp_dim,
dropout_rate=self.dropout_rate,
attention_dropout_rate=self.attention_dropout_rate,
name=f'encoderblock_{lyr}',
num_heads=self.num_heads)(
x, deterministic=not train)
encoded = nn.LayerNorm(name='encoder_norm')(x)Encoder 코드의 일부이다. position embedding을 더하고 여러 layer의 encoding block을 통과한다
cf) inductive bias
- ViT는 당연히 CNN보다 image-specific한 inductive bias가 훨씬 적다 => self-attention layer는 global하고, MLP layer만 local/translationally equivalent한데 얘네는 patch 단위로만 동작함
- 2D neightborhood structure 정보가 아키텍쳐에 주입되는 시점은 두 번
- 맨 처음에 patch 단위로 쪼개 flatten한 뒤 position embedding을 더할 때
- fine-tuning time에서 different resolution의 이미지로 adjust할 때 2D 위치를 고려하여 interpolation 수행
- 그 외 경우는 patch 간 all spatial relations를 from scratch부터 학습해야 함 => 따라서 large dataset 필요
cf) hybrid architecture
- inductive bias가 부족하다면, raw image patches 대신 CNN을 거친 feature map을 사용하면 되지 않을까 (rich information)
- patch embedding projection E가 CNN feature map에서 추출된 패치들에 적용되는거지
- (결론부터 말하면) medium scale에서는 성능 향상이 있었지만 large scale로 갈수록 raw image랑 큰 차이가 없었음
@nn.compact
def __call__(self, inputs, *, train):
x = inputs
# (Possibly partial) ResNet root.
if self.resnet is not None:
width = int(64 * self.resnet.width_factor)
# Root block.
x = models_resnet.StdConv(
features=width,
kernel_size=(7, 7),
strides=(2, 2),
use_bias=False,
name='conv_root')(
x)
x = nn.GroupNorm(name='gn_root')(x)
x = nn.relu(x)
x = nn.max_pool(x, window_shape=(3, 3), strides=(2, 2), padding='SAME')
# ResNet stages.
if self.resnet.num_layers:
x = models_resnet.ResNetStage(
block_size=self.resnet.num_layers[0],
nout=width,
first_stride=(1, 1),
name='block1')(
x)
for i, block_size in enumerate(self.resnet.num_layers[1:], 1):
x = models_resnet.ResNetStage(
block_size=block_size,
nout=width * 2**i,
first_stride=(2, 2),
name=f'block{i + 1}')(
x)
n, h, w, c = x.shape위 코드처럼 transformer encoder에 넣기 전에 ResNet 통과시키기도
Training
pre-train
- large dataset에 대해 수행 (ImageNet의 superset인 ImageNet-21k / JFT-300M)
fine-tune
- smaller downstream task에 대해 finetune 수행
- pre-train했던 prediction head 대신 zero-initialized D x K feed forward layer를 추가, K개의 classification
- pre-training 시보다 higher resolution으로 fine-tune 진행
- patch size는 동일하게 유지 => 시퀀스 길이가 더 늘어났을 것
- 이전의 position embedding은 사용하지 못함, 각 패치의 original image에서의 location을 고려하여 2D interpolation
model variants
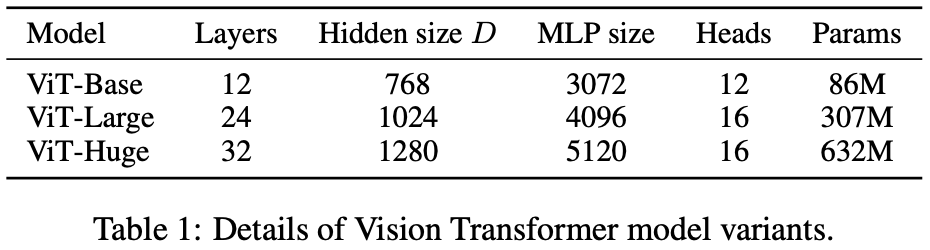
ex) ViT-L/16 은 "Large" variant with 16x16 input patch size를 의미한다
Analysis
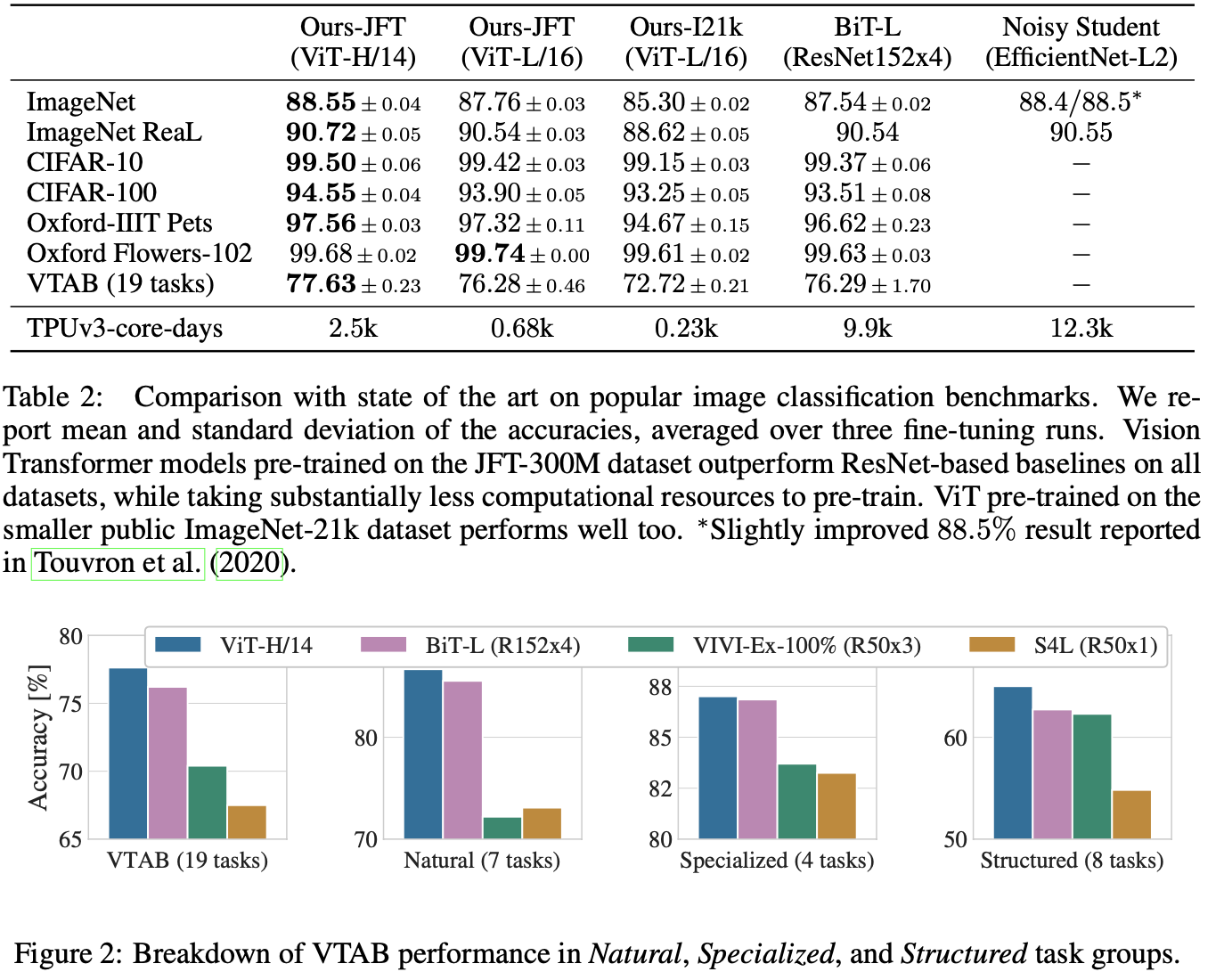
- JFT-300M 대규모 데이터셋으로 학습하니 ViT-L/16 모델이 이미 ResNet 성능을 능가했고, ViT-H/14는 더 개선되었다
- pre-training efficiency는 architecture choice 뿐 아니라 학습 파라미터(training schedule, optimizer, weight decay)에도 영향을 받는다
- smaller dataset에서의 성능을 높이기 위해 weight decay, dropout, label smoothing 등의 기법을 적용할 수 있다
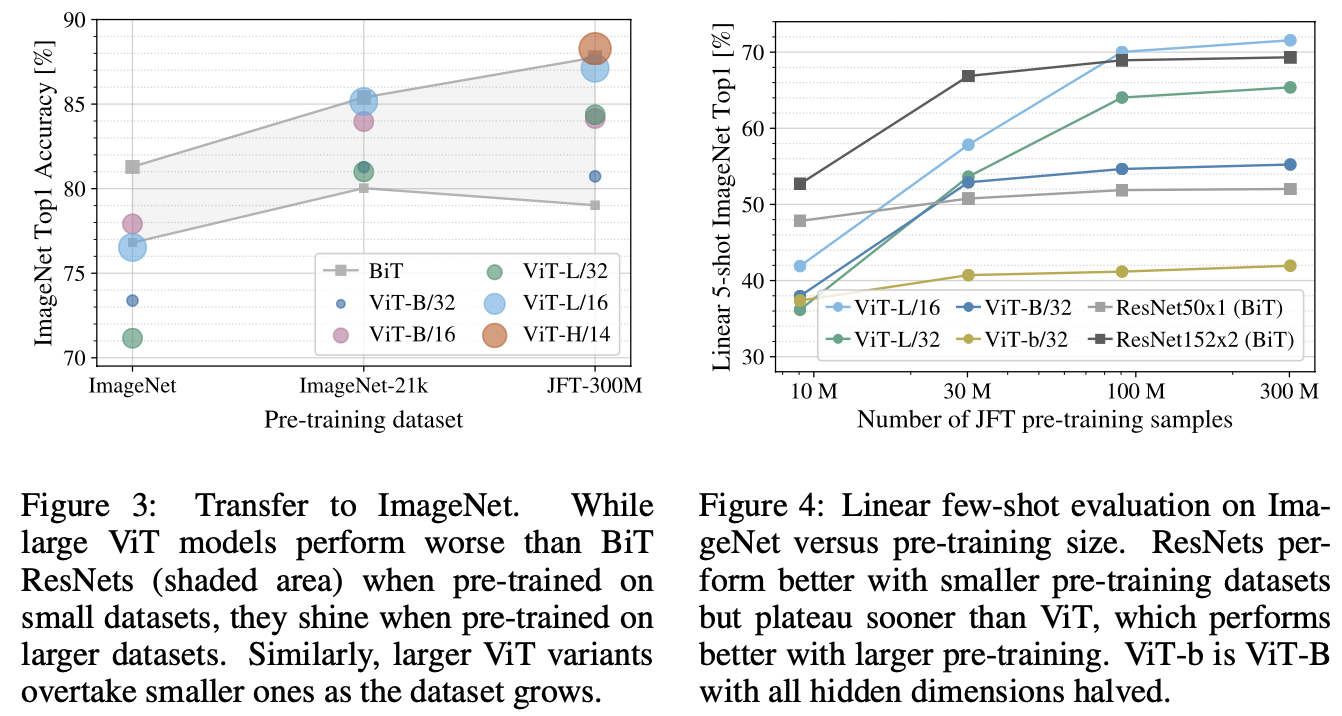
- figure 3을 보면 dataset이 충분히 커야 larger model의 이점을 확실히 누릴 수 있다
- figure 4를 보면 작은 dataset에 대해서는 ResNet이 우위를 점하고 있다 = convolutional inductive bias가 유용하게 작동한다
- 큰 dataset에 대해서는 pattern을 data로부터 직접적으로 학습하는 것이 충분하다 (오히려 좋다)
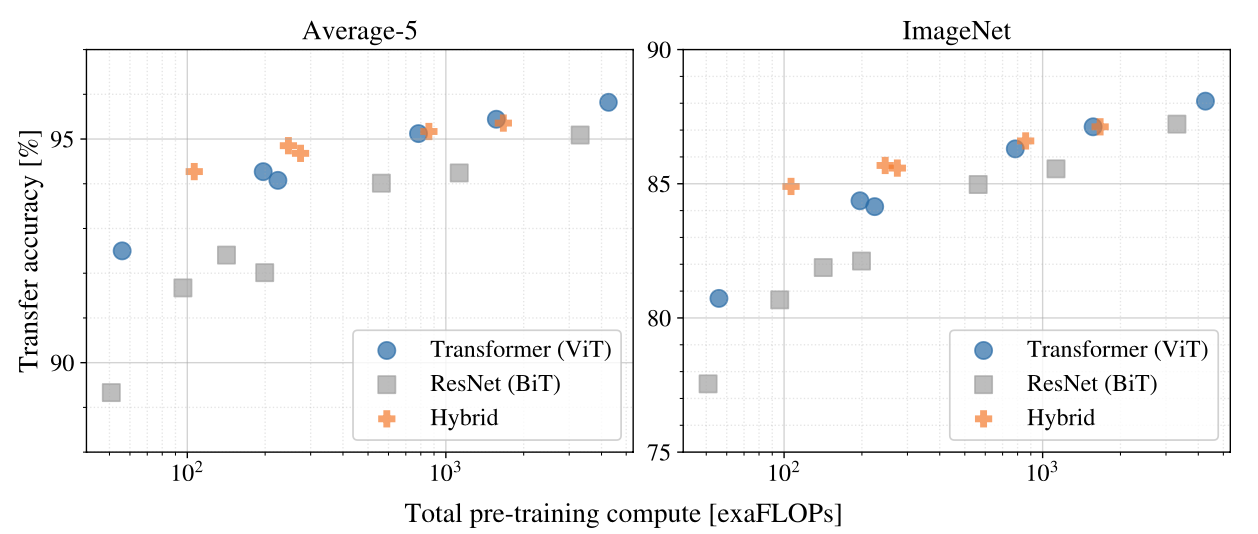
- 왼쪽 표를 보면 Transformer가 ResNet보다 훨씬 적은 compute power를 들이고서 동일한 accuracy를 달성했음을 알 수 있다 => performance/compute trade-off 우수
- hybrid 방식이 약간 더 좋지만 larger model로 갈수록 그 차이가 사라진다
- Transformer는 saturate하지 않는 듯하다 => model을 더 키워도 되겠네?

global한 이미지에서 classification을 위해 어느 부분에 집중(attention)해야 할지 잘 찾더라 (semantically relevant)

flattened patch를 lower-dimentional space (D-dim latent)로 project하는 filter를 visualize해보니 마치 CNN에서의 filter와 비슷해보이네요, 아마 pre-train을 많이 하게되면 비슷하게 동작하나봅니다
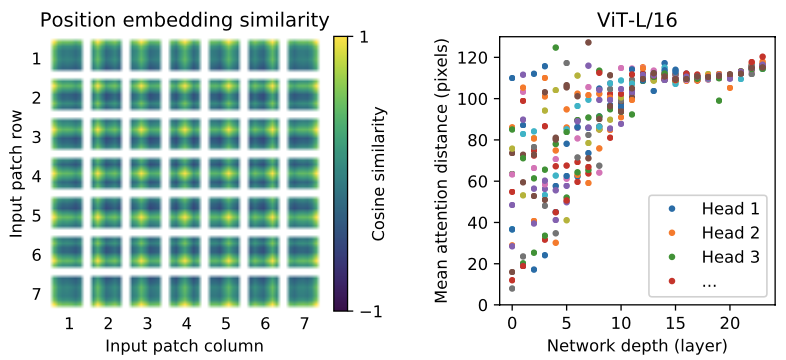
embedding vector도 visualize해보니 위치 정보를 잘 담고있는 것 같고요 (closer patches tend to have similar position embeddings), layer가 깊어질수록 attention distance도 잘 커지네요. CNN에서의 receptive field size 느낌으로 볼 수 있는데, head들이 "attend to most of the image"를 이미 잘 하고 있다고 봐도 되겠네요
NLP에서 핫하던 transformer 방식을 깔끔하게 vision에 도입한, 그러면서 ResNet 성능을 훌쩍 뛰어넘어버린,,
멋진 논문이네요