https://github.com/PKU-YuanGroup/LLaVA-CoT
GitHub - PKU-YuanGroup/LLaVA-CoT: LLaVA-CoT, a visual language model capable of spontaneous, systematic reasoning
LLaVA-CoT, a visual language model capable of spontaneous, systematic reasoning - PKU-YuanGroup/LLaVA-CoT
github.com
LLaVA-CoT Introduction
- 언어와 시각을 통합하고 효과적이고 체계적이며 심층적인 추론을 촉진하는 멀티모달 모델의 개발은 상당히 중요하다
- 초기 비전-언어 모델(VLM)의 한계
- direct prediction approach: 질문에 즉각적으로 짧은 답변을 생성하는 직접 예측 방식 사용
- 구조화된 추론 과정이 부족하여 논리적 추론을 요구하는 작업에 효과적이지 못함
- chain of thought 추론 도입
- 모델이 단계별로 추론하도록 장려하여 질문-응답 능력을 크게 향상시킴
- 하지만 대부분의 VLM은 추론 과정에서 오류나 환각된 출력을 자주 생성하는 문제가 있음
- why?
- 비체계적이고 비구조화된 추론 과정
- not systematic = 모델이 직접적인 추론 체인을 생성하지 않고, 다단계 추론에 관여하기만 함
- not structured = 모델이 자신이 어느 추론 단계에 있는지 명확히 식별하고 각 단계에서 해결해야 할 주요 과제를 이해하는 능력이 부족합니다.
- 문제와 사용 가능한 정보를 적절히 조직화하지 않고 응답을 시작하는 경우가 많았음
- 논리적 추론을 통해 결론에 이르는 대신 결론을 성급히 제시하고 이를 정당화하려고 시도함
- 잘못된 결론이 도입되면 모델은 일반적으로 잘못된 추론 경로를 계속 따르게 됨 (토큰 기반의 언어 모델 특성 상)
- 비체계적이고 비구조화된 추론 과정
OpenAI o1은 이런 이슈를 효과적으로 해결했지만 black box
- LLaVA-CoT
- 모델이 자율적으로 단계별 추론을 수행하는 능력을 향상시키기 위한 방법 제시
- 방법:
- LLaVA-CoT는 다음과 같은 네 가지 구별된 단계를 생성
- Summary (요약): 다가올 작업을 모델이 요약하는 간단한 개요.
- Caption (캡션): 이미지(있을 경우)의 관련 부분을 설명하여 질문과 관련된 요소에 초점을 맞춤.
- Reasoning (추론): 모델이 질문을 체계적으로 고려하는 상세한 분석.
- Conclusion (결론): 이전 추론에 기반한 최종 응답을 제공하는 간결한 답변.
- 각 단계를 나타내기 위해 전용 태그(e.g., <SUMMARY>...</SUMMARY>)를 사용하여 시작과 끝을 표시 ⇒ 추론 과정에서 명확성을 유지하도록 함
- 먼저 문제와 알려진 정보를 조직하고, 상세한 사고 과정을 거쳐 결론을 도출함으로써 구조화된 사고를 촉진함
- 데이터셋 구축: GPT-4o를 사용하여 단계별로 응답을 생성하여 LLaVA-CoT-100k 데이터셋을 구축하고, 이를 통해 모델을 supervised fine tuning으로 학습
- LLaVA-CoT는 다음과 같은 네 가지 구별된 단계를 생성
- 효율적인 inference time scaling 가능해짐
- 기존 스케일링 방법(best-of-N 샘플링이나 문장 수준 빔 서치와 같은 전통적인 방법)은 제약이 많음
- stage-level beam search method
- 각 단계에서 여러 후보 결과를 생성하고, 최상의 것을 선택하여 생성 과정을 계속하는 새로운 방법
- 성능의 안정성과 신뢰성을 향상시켜, 안정적이고 정확한 결과를 달성
- 기여 요약
- LLaVA-CoT 소개: 구조적 사고와 추론이 필요한 작업에서 뛰어난 성능을 보이는 체계적 추론을 위한 비전 언어 모델 도입
- 추론 시 스케일링 가능성 입증: stage-level beam search를 사용하는 LLaVA-CoT는 추론 시 스케일링이 가능하여, 계산 자원을 증가시킴으로써 성능을 더욱 향상시킬 수 있음
- 광범위한 실험을 통한 검증: 다양한 벤치마크에서의 광범위한 실험을 통해 더 큰 규모의 비공개 모델보다 우수한 성능을 달성하여, 멀티모달 추론에서 LLaVA-CoT의 효과를 입증
관련 작업
대형 언어 모델을 활용한 시각적 추론
- 시각적 추론은 모델의 시각적 인식 능력과 고차원적인 인지 능력을 필요로 함
- 평가를 위한 과제:
- VQA (Visual Question Answering): 시각적 콘텐츠와 텍스트 질문에 기반하여 모델이 답변
- Visual Entailment: 텍스트 설명과 시각적 콘텐츠의 일치성을 결정
- 전통적인 비전-언어 모델에서는 neural symbolic 접근법 사용
- VLM은 LLM의 고급 추론 능력을 활용하여 시각적 과제를 해석
- 인지에 초점을 맞춘 시각적 토큰 생성을 위해 시각적 인코딩 전략을 최적화하여 시각적 추론을 강화
대형 언어 모델에서의 Chain-of-thought
- CoT ⇒ LLM이 상식 추론, 논리적 추론 등 어려운 질문에 직면했을 때 단계별 추론 경로를 제공
- 질문을 여러 개의 추론 단계로 분해하고, 이를 연결하여 모델이 복잡한 문제의 결과를 단계별로 생성하도록 안내
2.3 추론 시 스케일링
- 두 가지 주요 범주
- 외부 검증자에 의존하여 선택하는 방법
- 외부 검증자 없이 독립적으로 작동하는 방법
- 외부 검증자 없이 작동하는 추론 시 스케일링 방법에는
- 다수결 투표
- 표준 답변이 있는 특정 유형의 문제에 효과적이지만, 개방형 과제에는 적합하지 않음
- Best-of-N 검색
- N개의 완전한 답변을 생성하고, 모델이 최상의 응답을 선택하도록 함
- 그러나 전체 답변을 생성하여 선택하는 것은 정확성 평가를 복잡하게 만들 수 있음
- 문장 수준 빔 서치
- 여러 후보 문장을 생성하고, 최상의 것을 선택하여 이 과정을 반복
- 너무 세밀한 수준에서 작동하여, 모델이 문장 단위로 응답의 품질을 효과적으로 평가하기 어렵게 만듦
- 다수결 투표
Methodology
구조화된 사고를 통해 LLaVA-CoT는 체계적이고 효율적인 추론 과정을 달성함
복잡한 추론이 필요한 작업에서의 robustness와 accuracy를 보장함
3.1 구조화된 사고를 통한 추론 능력 향상
체계적이고 심층적인 추론을 수행할 수 있는 extended chains of reasoning을 가진 VLM을 만들어보자

3.1.1 추론 단계
LLaVA-CoT는 답변 생성 과정을 네 개의 구조화된 추론 단계로 분해
- 요약 단계(Summary Stage): 질문에 대한 고수준의 요약 해석을 제공하여 해결하려는 문제의 주요 측면을 개략적으로 설명
- 캡션 단계(Caption Stage): 이미지가 있을 경우, LLaVA-CoT는 질문과 관련된 시각적 요소에 대한 간결한 개요를 제공하여 멀티모달 입력을 이해
- 추론 단계(Reasoning Stage): 초기 요약을 바탕으로 LLaVA-CoT는 구조화되고 논리적인 추론을 수행하여 예비 답변을 도출
- 결론 단계(Conclusion Stage): 이전의 추론에 기반하여 답변을 종합. 이 단계에서의 출력은 사용자에게 제공되는 직접적인 응답이며, 이전의 세 단계는 LLaVA-CoT의 내부 "숨겨진 단계"로서 추론 과정을 나타냄 (사용자의 요구에 따라 response 조정)
- external prompt engineering framework나 추가적인 prompting 필요 없음
- 네 쌍의 특수 태그를 제공: <SUMMARY></SUMMARY>, <CAPTION></CAPTION>, <REASONING></REASONING>, <CONCLUSION></CONCLUSION>
- 모델은 자체 판단에 따라 이러한 태그를 필요에 따라 자동으로 선택하고 각 단계를 활성화함, 모든 단계는 single inference pass에서 완료됨 (like OpenAI o1)
- 이런 구조화된 접근법은 모델이 추론 과정을 독립적으로 관리할 수 있게 하여, 복잡한 추론 작업에서의 적응력과 성능을 향상시킴
3.1.2 데이터 준비 및 모델 훈련

- 기존 VQA 데이터셋은 LLaVA-CoT 모델을 훈련시키는 데 필요한 상세한 추론 과정 부재
- VQA 데이터셋에서 샘플을 통합하여 총 99,000개의 이미지 QA 쌍(각 쌍은 single, multi rounds)을 수집
- GPT-4o를 사용하여 요약, 캡션, 추론, 결론을 포함한 상세한 추론 과정을 생성하고 이를 LLaVA-CoT-100k 데이터셋으로 컴파일

- 일반 VQA 데이터셋: ShareGPT4V(GPT-4V와의 상호 작용에서 다중 턴 질문-답변 데이터), ChartQA(차트와 그래프 해석), A-OKVQA(외부 지식에 중점), DocVQA(문서 기반 질문), PISC(사회적 관계를 이해), CLEVR(객체 속성, 공간 관계, 계산 작업)
- 과학 대상 VQA 데이터셋: 기하학적 추론을 위한 GeoQA+, 과학적 질문을 목표로 하는 AI2D와 ScienceQA, CLEVR-Math는 시각적 맥락에서의 산술 분석
모델 훈련
- 새롭게 구축한 LLaVA-CoT-100k 데이터셋으로 감독된 파인튜닝(SFT), 전체 parameter 학습
- Llama-3.2-11B-Vision-Instruct [42] 모델을 기본 모델로
- 8개의 H100 GPU가 있는 단일 노드에서 수행
3.2 Stage-level Beam Search를 사용한 효과적인 추론 시간 스케일링
훈련 후 또다른 목표는 추론 중에 모델의 추론 능력을 더욱 향상시키는 것
⇒ LLaVA-CoT의 stage-based outputs을 활용하여 추론 시간 스케일링 달성
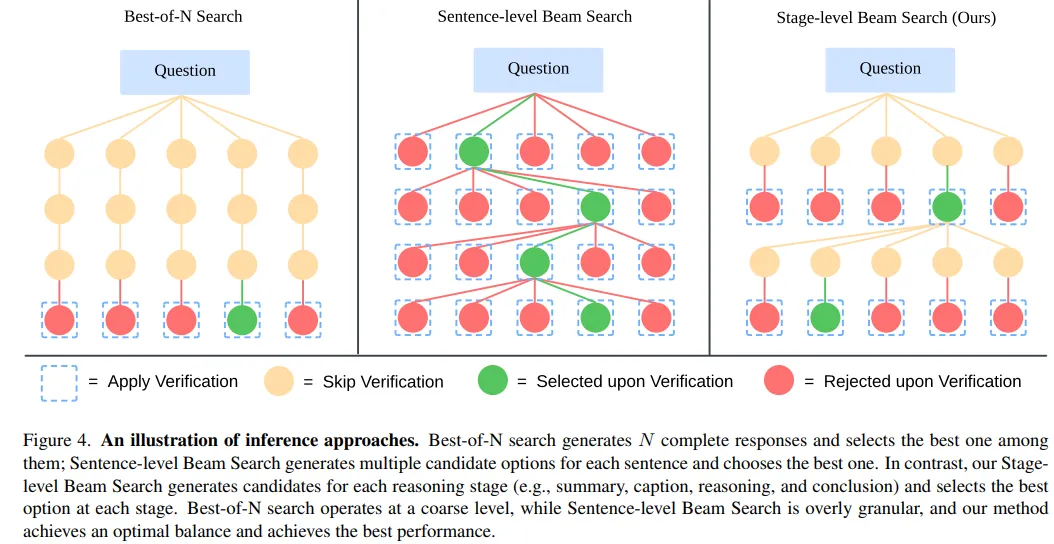
- 첫 번째 단계에 대해 N개의 응답을 샘플링
- 무작위로 2개의 응답을 샘플링하고, 모델이 어느 것이 더 나은지 결정하게 하여 더 나은 응답 유지
- N-1번 반복하여 최상의 응답 유지
- 다음 단계에 대해 N개의 응답을 샘플링하고, 모든 단계가 처리될 때까지 2-4단계를 반복
- LLaVA-CoT의 구조화된 출력 디자인이 이러한 접근법을 가능하게 함
- 추론 시간 스케일링이 적용되지 않은 경우, 모델은 올바른 추론 단계를 생성하지만, 추론 과정에서 구체적인 답변에 잘 도달하지 못함 ⇒ 모델이 결론 단계에서 추측을 하게 만들어 잘못된 결과를 초래
- 추론 시간 스케일링을 사용하면 모델은 최종 결과로 이어지는 추론 단계를 유지하여 답변의 정확성을 보장
분석
LLaVA-CoT와 기본 모델 Llama-3.2-11B-Vision-Instruct 6개의 멀티모달 벤치마크에서 비교해봤더니
→ 평균 6.9%의 성능 향상
→ 일반적인 VQA, 수학적 추론, 과학 VQA, 환각 제어 작업에서 뛰어난 성능을 입증
원본 Q&A 쌍을 직접 사용한 모델보다 LLaVA-CoT-100k 데이터셋으로 훈련한 모델이 상당한 성능 향상 보임
구조화된 태그 중요함 (facilitate inference, 성능 향상)
stage-level beam search는 복잡한 추론 작업에서 높은 정확도를 달성하면서도 계산 효율성 유지, beam 크기 늘릴수록 성능 지속적으로 향상 (scaling 가능성)
일부 비공개 모델(GPT-4o-mini, Gemini-1.5-pro)보다도 뛰어난 성능을 보여 구조화된 추론 접근법의 효과 확인
'AI > NLP (LLM)' 카테고리의 다른 글
| [논문 리뷰] Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models (1) | 2024.11.28 |
|---|---|
| Attention Is All You Need ! (1) | 2024.11.01 |
| [논문 리뷰] PARROT: MULTILINGUAL VISUAL INSTRUCTION TUNING (1) | 2024.10.31 |
| LLaVA-OneVision (opensource VLM) (0) | 2024.08.15 |
| 업스테이지 Solar LLM - tool RAG (0) | 2024.05.19 |